JetBrains Releases Mellum2: A 12B MoE Model for Fast, Specialized Tasks in Multi-Model AI Pipelines
JetBrains has released Mellum2, a 12B Mixture-of-Experts model designed for specialized software engineering tasks, now open-sourced under the Apache 2.0 license. It functions as a "focal model" within larger AI systems, prioritizing speed and efficiency for tasks like code generation and debugging over standalone frontier model capabilities.
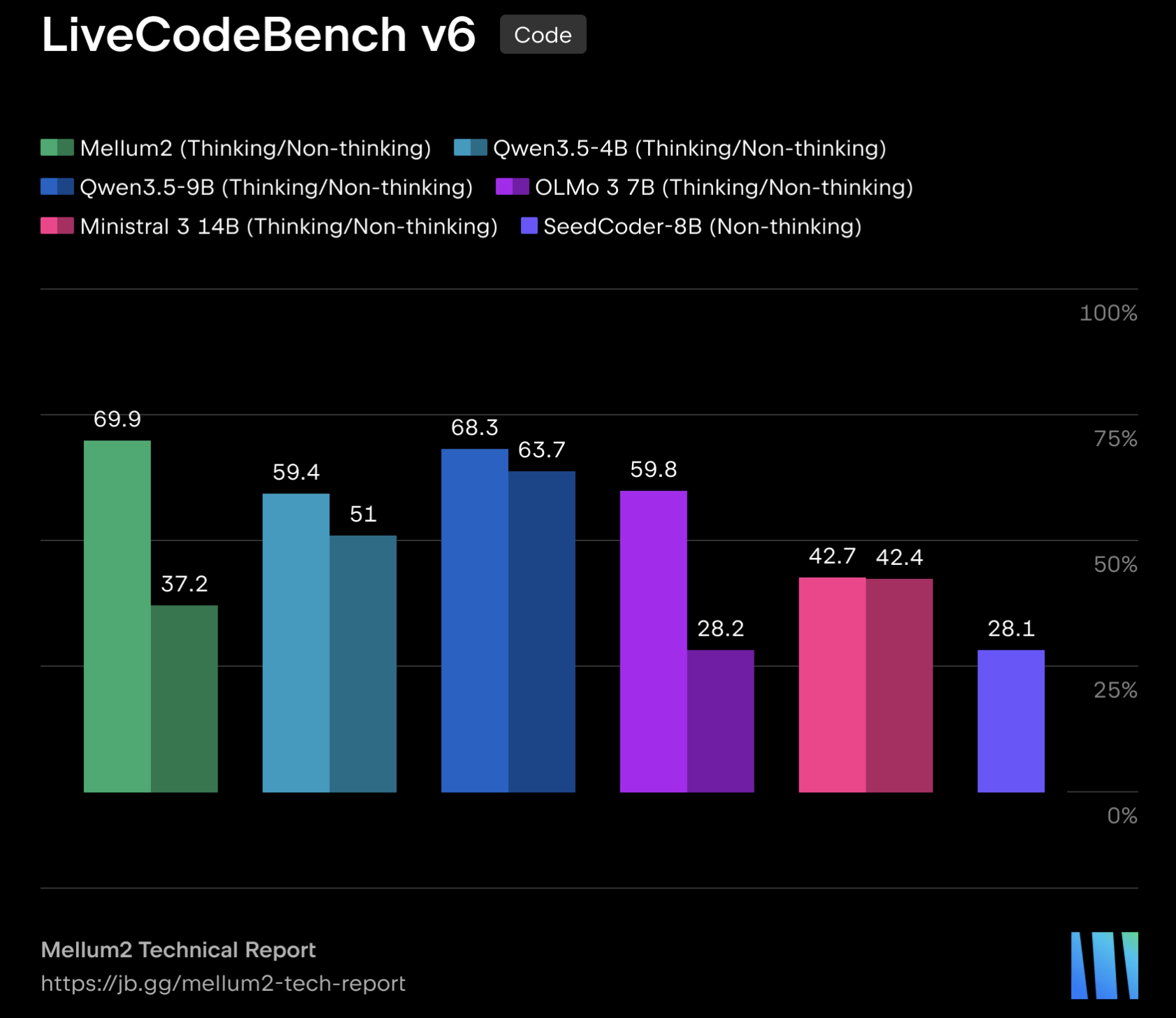
JetBrains has officially released Mellum2, an advanced 12B Mixture-of-Experts (MoE) model. This successor to the 4B dense model, Mellum, is primarily specialized in software engineering tasks, encompassing capabilities like code generation, editing, debugging, multi-step reasoning, and conversational programming assistance. The weights for Mellum2 have been open-sourced under the Apache 2.0 license, promoting wider accessibility and collaboration. Its MoE architecture employs 64 experts, activating 8 per token, which helps maintain computational efficiency equivalent to a 2.5B dense model while offering greater capacity for specialization. The model is trained on a vast dataset of approximately 10.6 trillion tokens, with a curriculum that progressively shifts from diverse web content to curated code and mathematical data. The training process utilized the Muon optimizer with FP8 hybrid precision.
Mellum2 is positioned by the JetBrains team as a "focal model" rather than a standalone replacement for larger, frontier models. It is designed to excel as a fast, specialized component within broader AI pipelines, handling high-frequency and latency-sensitive operations. This approach optimizes its utility in scenarios requiring efficient and targeted AI assistance.
The model underwent a sophisticated training pipeline, including pre-training, context window extension to 128K tokens using a layer-selective YaRN method, and two stages of post-training. The post-training phases involved supervised fine-tuning (SFT) followed by reinforcement learning with verifiable rewards (RLVR) across various tasks such as math, executable coding, and instruction following.
Two distinct variants of Mellum2 are available: Instruct and Thinking. The Instruct variant is optimized for low-latency tasks, providing direct answers for tool use and instruction following. In contrast, the Thinking variant generates an explicit reasoning trace before delivering its final answer, making it suitable for complex debugging, multi-step planning, and agentic workflows where detailed reasoning is crucial. JetBrains has also provided installation instructions and usage examples for integrating Mellum2 into existing AI frameworks, including vLLM and Hugging Face Transformers.
Related articles
Build real agentic apps using CUGA: two dozen working examples on a lightweight harness
CUGA, IBM's open-source Agent Harness, simplifies building agentic applications by handling infrastructure, allowing developers to focus on tools and prompts. It offers pre-assembled components for planning, execution, and state management, significantly reducing development time. CUGA has topped agent benchmarks like AppWorld and WebArena.
OpenAI launches new initiative to help find and patch open source bugs
OpenAI has launched "Patch the Planet," a new initiative in partnership with cybersecurity firm Trail of Bits, to enhance the security of open-source projects. This program aims to assist maintainers in identifying and patching bugs, utilizing OpenAI's AI-powered security tools while reducing the burden on project teams.
PP-OCRv6 on Hugging Face: 50-Language OCR from 1.5M to 34.5M Parameters
Baidu has released PP-OCRv6, an advanced optical character recognition (OCR) model supporting 50 languages. Available on Hugging Face, this version significantly improves accuracy and efficiency across various parameter sizes, from 1.5 million to 34.5 million, marking a substantial leap in multilingual OCR technology.