Stability AI Releases Stable Audio 3: A Family of Fast Latent Diffusion Models for Audio Generation and Editing
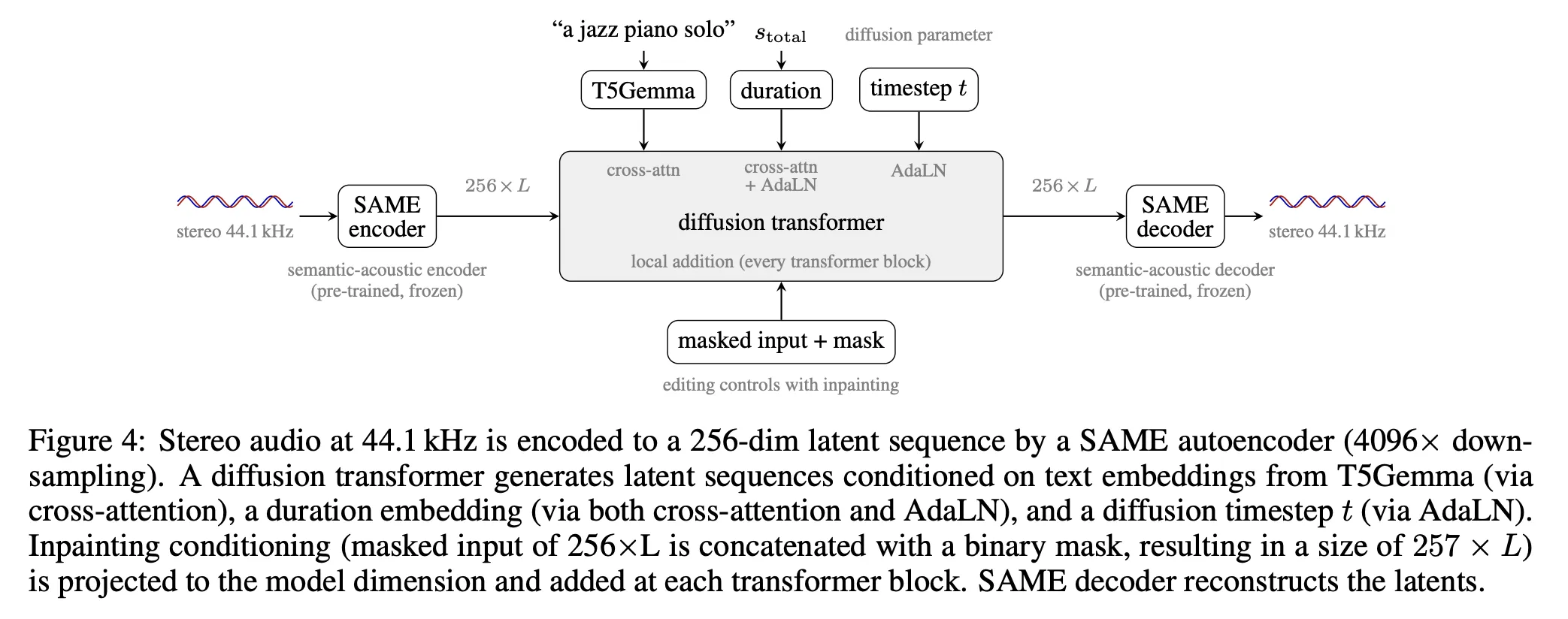
Stability AI has launched Stable Audio 3, a new suite of latent diffusion models designed for generating instrumental music and sound effects. This release includes open-weight versions suitable for various hardware, demonstrating strong performance in audio quality and efficiency.
Stability AI has unveiled Stable Audio 3, a new family of latent diffusion models. These models are specifically designed for generating instrumental music and sound effects. The release emphasizes accessibility with open-weight versions for small and medium variants.These models are optimized for performance across different hardware. The small variant operates efficiently on a MacBook Pro M4 CPU, while the medium variant is compatible with consumer GPUs equipped with 8 GB of VRAM.Stable Audio 3 utilizes a sophisticated three-stage training pipeline, which includes flow matching, distillation warmup, and adversarial post-training. This methodology enables the generation of high-quality stereo audio at 44.1 kHz.The efficacy of Stable Audio 3 is highlighted by its performance on benchmarks. The medium variant achieved an FAD score of 0.369 on the BBC Sound Effects benchmark (at 5 seconds), outperforming all other open-weight baselines evaluated in the accompanying paper.
Related articles
Build real agentic apps using CUGA: two dozen working examples on a lightweight harness
CUGA, IBM's open-source Agent Harness, simplifies building agentic applications by handling infrastructure, allowing developers to focus on tools and prompts. It offers pre-assembled components for planning, execution, and state management, significantly reducing development time. CUGA has topped agent benchmarks like AppWorld and WebArena.
OpenAI launches new initiative to help find and patch open source bugs
OpenAI has launched "Patch the Planet," a new initiative in partnership with cybersecurity firm Trail of Bits, to enhance the security of open-source projects. This program aims to assist maintainers in identifying and patching bugs, utilizing OpenAI's AI-powered security tools while reducing the burden on project teams.
PP-OCRv6 on Hugging Face: 50-Language OCR from 1.5M to 34.5M Parameters
Baidu has released PP-OCRv6, an advanced optical character recognition (OCR) model supporting 50 languages. Available on Hugging Face, this version significantly improves accuracy and efficiency across various parameter sizes, from 1.5 million to 34.5 million, marking a substantial leap in multilingual OCR technology.