StepFun Releases StepAudio 2.5 Realtime: An End-to-End Voice Model with Roleplay-Specific RLHF and Paralinguistic Comprehension
StepFun has released StepAudio 2.5 Realtime, an end-to-end real-time speech large language model with customizable personas. This model stands out for its unique architecture, which includes persona-specific RLHF for consistent roleplay and advanced paralinguistic comprehension for understanding non-verbal cues.
StepFun, an AI laboratory based in Shanghai, has unveiled StepAudio 2.5 Realtime, an end-to-end real-time speech large language model. This innovative model features fully customizable persona capabilities and supports both Chinese and English. It represents a significant advancement by unifying speech recognition, reasoning, and synthesis into a single system, departing from traditional pipeline-based approaches.
The model's architecture incorporates several key innovations. StepFun utilized algorithmic augmentation to create a vast persona feature matrix from over 10,000 high-quality natively authored personas, supplemented by millions of real-world conversational samples. This approach aims to achieve stable performance across diverse and challenging conversational topics.
One notable innovation is the application of Reinforcement Learning from Human Feedback (RLHF) specifically optimized for persona consistency in roleplay scenarios. This addresses the common issue of models exhibiting "out-of-character" behavior during conversations, ensuring the model maintains its defined persona throughout interactions.
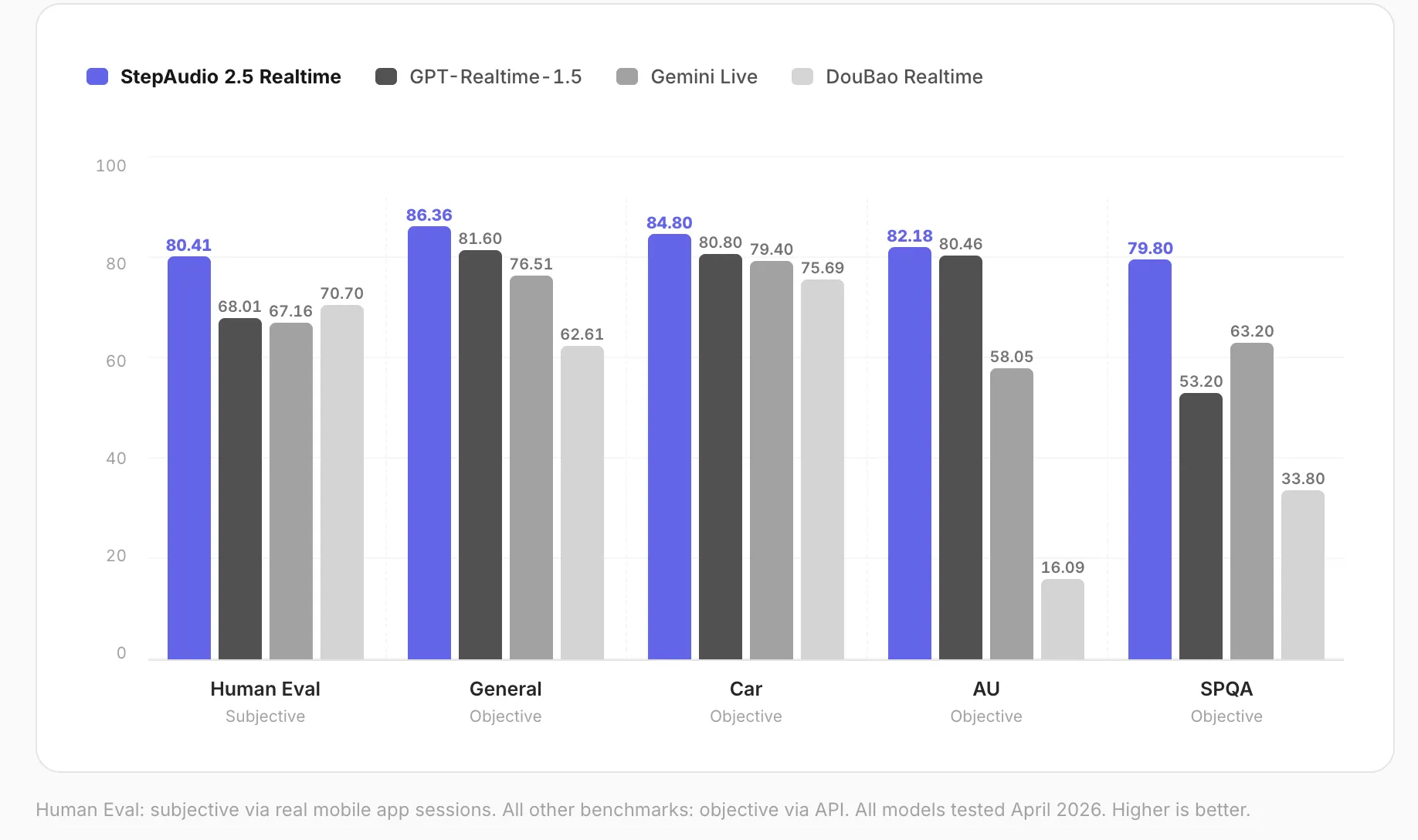
StepAudio 2.5 Realtime also excels in paralinguistic perception, which involves understanding non-verbal acoustic information such as tone, speaking rate, pauses, and laughter. By analyzing these elements, the model can discern a user's mood and intentions. This capability allows for "global scene-level tonal setting" and "intra-sentence detail sculpting," enabling the model to set an overall emotional register while fine-tuning acoustic details within sentences.
The model demonstrated strong performance in paralinguistic comprehension, scoring 82.18 on a benchmark that assesses perception of vocal speed, emotion, and age. Comprehensive subjective and objective evaluations were conducted against leading real-time voice models across various dimensions.
Related articles
Build real agentic apps using CUGA: two dozen working examples on a lightweight harness
CUGA, IBM's open-source Agent Harness, simplifies building agentic applications by handling infrastructure, allowing developers to focus on tools and prompts. It offers pre-assembled components for planning, execution, and state management, significantly reducing development time. CUGA has topped agent benchmarks like AppWorld and WebArena.
OpenAI launches new initiative to help find and patch open source bugs
OpenAI has launched "Patch the Planet," a new initiative in partnership with cybersecurity firm Trail of Bits, to enhance the security of open-source projects. This program aims to assist maintainers in identifying and patching bugs, utilizing OpenAI's AI-powered security tools while reducing the burden on project teams.
PP-OCRv6 on Hugging Face: 50-Language OCR from 1.5M to 34.5M Parameters
Baidu has released PP-OCRv6, an advanced optical character recognition (OCR) model supporting 50 languages. Available on Hugging Face, this version significantly improves accuracy and efficiency across various parameter sizes, from 1.5 million to 34.5 million, marking a substantial leap in multilingual OCR technology.