Alibaba Qwen Team Introduces Qwen3.5-LiveTranslate-Flash: Real-Time Multimodal Interpretation Across 60 Languages at 2.8-Second Latency
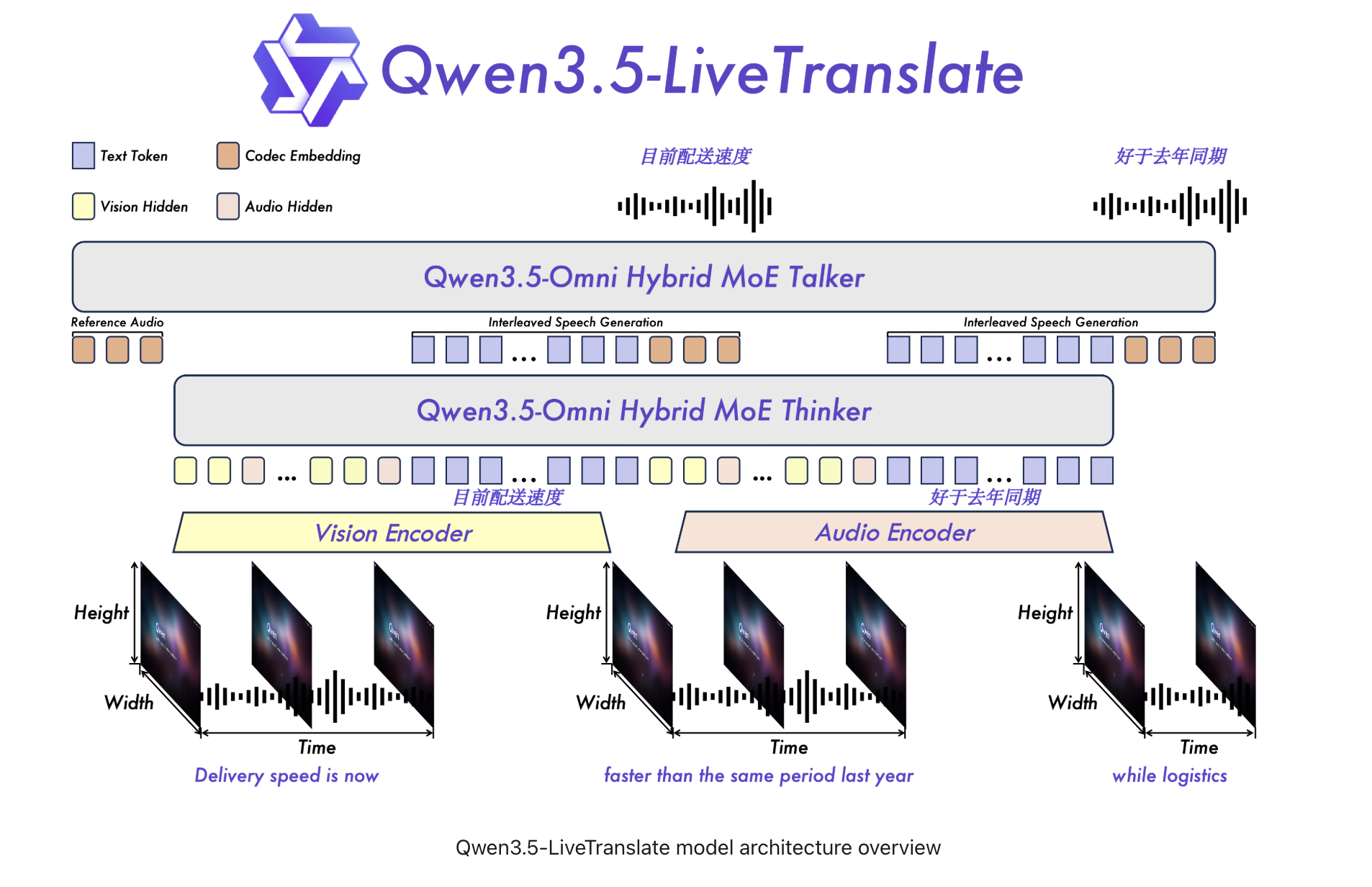
Alibaba's Qwen team has unveiled Qwen3.5-LiveTranslate-Flash, a new real-time multimodal interpretation model. This advanced system significantly reduces translation latency and expands language support, making real-time communication more seamless and natural across 60 languages. It achieves this through continuous output streaming, visual context analysis, speaker voice cloning, and dynamic keyword configuration, setting a new standard for enterprise-grade translation.
Alibaba's Qwen team has launched Qwen3.5-LiveTranslate-Flash, a real-time multimodal interpretation model. It achieves significantly lower latency of 2.8 seconds and expands input language coverage to 60 languages, addressing the complex challenges of simultaneous interpretation. The model also adds speech output capabilities in 29 languages, marking a substantial expansion in linguistic versatility. This reduces the need for language-specific model switching in global enterprise settings.
The model's improved latency stems from processing "reading units" rather than waiting for full sentences. It continuously streams output by committing to a translation once sufficient meaning accumulates in a segment. This method refines the underlying logic of semantic unit prediction, leading to a 200-millisecond reduction in delay.
Qwen3.5-LiveTranslate-Flash integrates visual information with audio, analyzing on-screen text, objects, lip movements, and gestures. This multimodal approach allows the system to fill gaps and sharpen translations when audio quality is poor or words are phonetically ambiguous. This feature is crucial for real-world scenarios where pristine audio conditions are rarely guaranteed.
Another key advancement is the cloning of the speaker's characteristic voice features. Unlike standard systems that use generic synthesis voices, Qwen3.5-LiveTranslate-Flash recreates the original speaker's voice in the translated output after hearing just one spoken sentence. This makes the translated communication sound more human and natural to the listener.
To address the persistent issue of proper nouns and specialized vocabulary, the model offers dynamic keyword configuration. Developers can inject glossaries of domain-specific terms at runtime, significantly enhancing the accuracy of translations for medical, legal, or technical content. This closes a critical gap for enterprise deployments requiring precise terminology.
Benchmarked against FLEURS and CoVoST2, Qwen3.5-LiveTranslate-Flash outperforms major commercial alternatives in translation quality across diverse language pairs and real acoustic conditions.
Related articles
The AI world is getting ‘loopy’
AI models are taking a significant leap forward with the adoption of "agentic loops," where AI agents continuously prompt each other to improve code and solve complex problems. This approach, though potentially resource-intensive, promises to unlock new levels of autonomous problem-solving and efficiency in AI applications.
Codex-maxxing for long-running work
Codex is increasingly being used by organizations to support long-running projects that go beyond a single prompt. This whitepaper by Jason Liu offers practical strategies for leveraging Codex as a persistent workspace, managing complex workflows and sustaining progress.
Nobel laureate John Jumper is leaving DeepMind for rival Anthropic
Nobel laureate John Jumper is departing Google DeepMind to join its competitor, Anthropic, after dedicating nearly nine years to DeepMind, where he led the AlphaFold team. Jumper, who shared a Nobel Prize for his work on AlphaFold, expressed gratitude for his time at DeepMind while looking forward to new endeavors.