MEMO: A Modular Framework for Training a Dedicated Memory Model on New Knowledge Without Modifying LLM Parameters
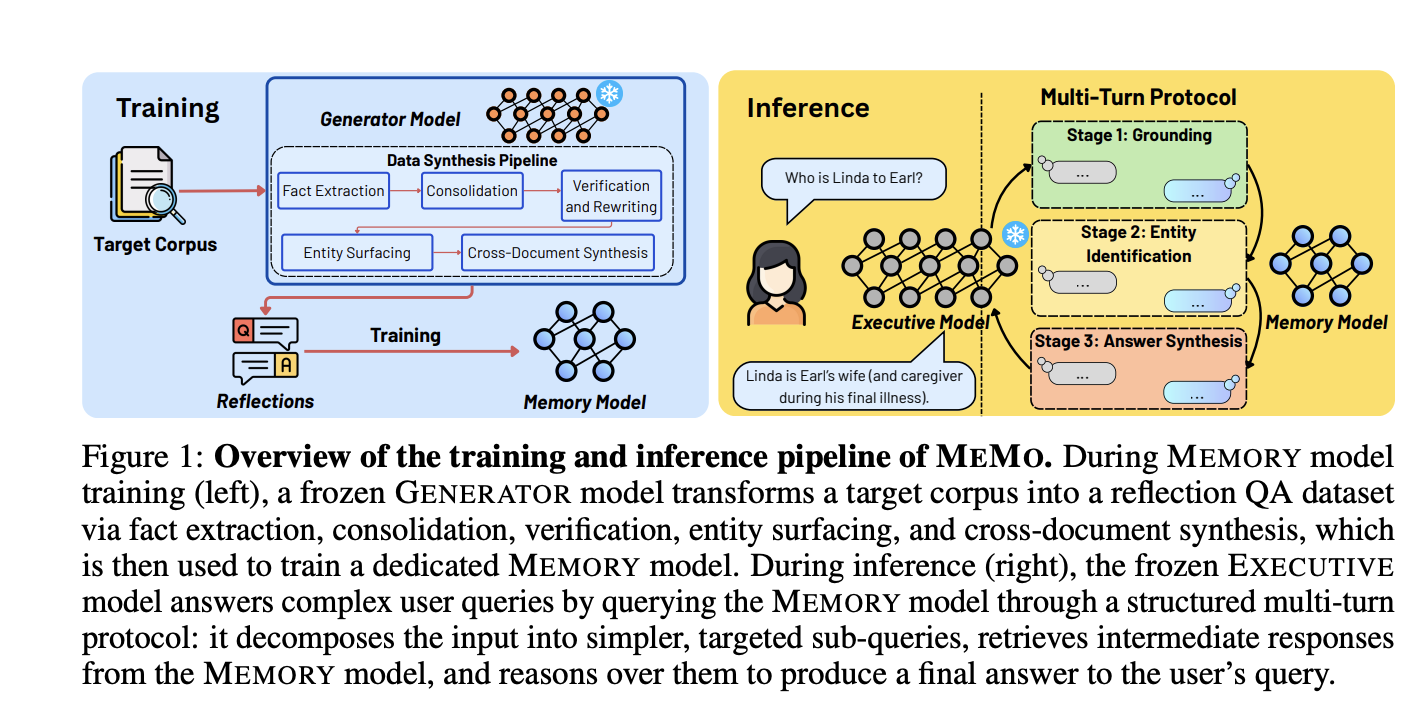
Researchers developed MEMO, a new framework that enables large language models (LLMs) to integrate new information without altering their core parameters. This modular approach encodes external knowledge into a separate, trainable memory model, enhancing adaptability and efficiency.
Researchers from NUS, MIT, and A*STAR have introduced MEMO, a novel modular framework. This framework is designed to train a dedicated memory model on new knowledge. It does so without modifying the parameters of the underlying large language model (LLM).
MEMO
Related articles
The AI world is getting ‘loopy’
AI models are taking a significant leap forward with the adoption of "agentic loops," where AI agents continuously prompt each other to improve code and solve complex problems. This approach, though potentially resource-intensive, promises to unlock new levels of autonomous problem-solving and efficiency in AI applications.
Codex-maxxing for long-running work
Codex is increasingly being used by organizations to support long-running projects that go beyond a single prompt. This whitepaper by Jason Liu offers practical strategies for leveraging Codex as a persistent workspace, managing complex workflows and sustaining progress.
Nobel laureate John Jumper is leaving DeepMind for rival Anthropic
Nobel laureate John Jumper is departing Google DeepMind to join its competitor, Anthropic, after dedicating nearly nine years to DeepMind, where he led the AlphaFold team. Jumper, who shared a Nobel Prize for his work on AlphaFold, expressed gratitude for his time at DeepMind while looking forward to new endeavors.