NVIDIA AI Releases Nemotron-Labs-Diffusion: A Tri-Mode Language Model with 6× Tokens Per Forward Over Qwen3-8B
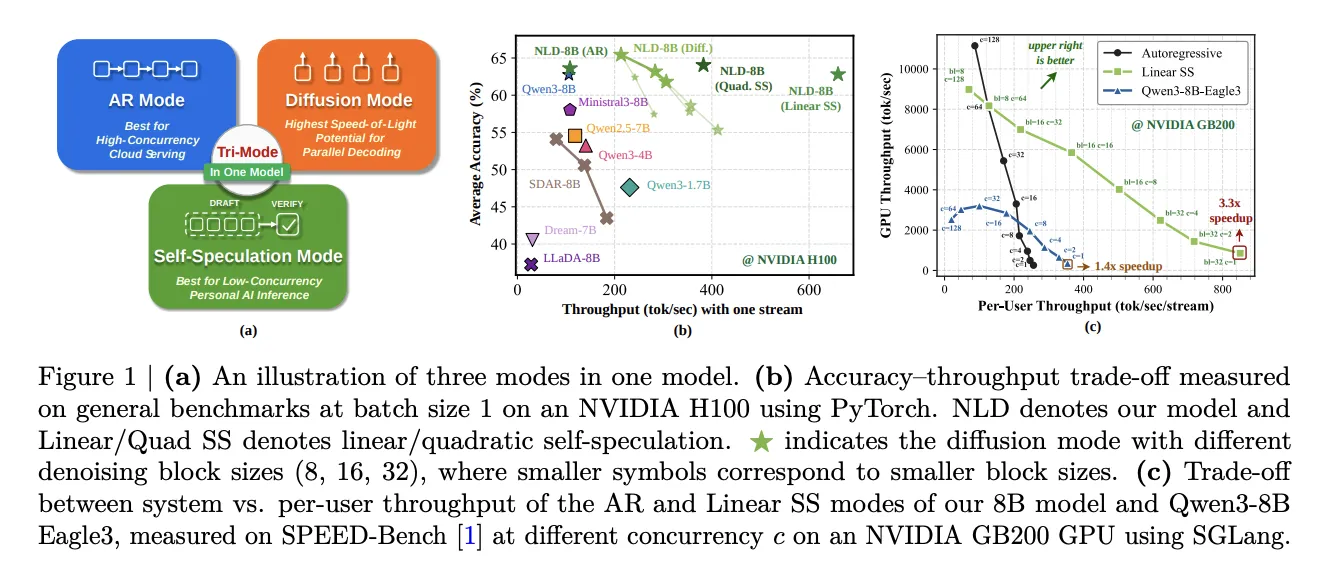
NVIDIA introduces Nemotron-Labs-Diffusion, a language model with three decoding modes: autoregressive, diffusion, and self-speculation. This innovation offers up to six times more tokens per forward pass compared to traditional models, enhancing efficiency without sacrificing accuracy. This novel architecture allows for flexible deployment across various computational environments. Each of its decoding modes is tailored for specific deployment contexts, from high-concurrency cloud serving to handling multiple tokens in parallel. This advancement sets a new benchmark in language model performance and adaptability. This model is trained using a unique joint AR-diffusion objective that ensures robust performance across different tasks and scales.
NVIDIA has introduced Nemotron-Labs-Diffusion, a language model family that integrates three decoding modes within a single architecture. This model supports autoregressive (AR) decoding, diffusion-based parallel decoding, and self-speculation decoding. Available in 3B, 8B, and 14B parameter sizes, the family also includes base, instruct, and vision-language variants, providing versatility for various applications. This unified approach addresses the limitations of traditional models by enhancing processing efficiency and adaptability.
Traditional autoregressive language models process text one token at a time, creating a sequential dependency that restricts GPU parallelism and leads to low hardware utilization in typical deployment scenarios. Diffusion language models, conversely, denoise multiple tokens in parallel per forward pass, offering higher throughput. While previous diffusion models often lagged in accuracy, Nemotron-Labs-Diffusion
Related articles
The AI world is getting ‘loopy’
AI models are taking a significant leap forward with the adoption of "agentic loops," where AI agents continuously prompt each other to improve code and solve complex problems. This approach, though potentially resource-intensive, promises to unlock new levels of autonomous problem-solving and efficiency in AI applications.
Codex-maxxing for long-running work
Codex is increasingly being used by organizations to support long-running projects that go beyond a single prompt. This whitepaper by Jason Liu offers practical strategies for leveraging Codex as a persistent workspace, managing complex workflows and sustaining progress.
Nobel laureate John Jumper is leaving DeepMind for rival Anthropic
Nobel laureate John Jumper is departing Google DeepMind to join its competitor, Anthropic, after dedicating nearly nine years to DeepMind, where he led the AlphaFold team. Jumper, who shared a Nobel Prize for his work on AlphaFold, expressed gratitude for his time at DeepMind while looking forward to new endeavors.