Zyphra Release Zamba2-VL: Hybrid Mamba2–Transformer Vision-Language Models That Cut Time-to-First-Token by About an Order of Magnitude
Zyphra has launched Zamba2-VL, a new family of open vision-language models that significantly reduces the time to first token. These models achieve competitive accuracy with a hybrid Mamba2–Transformer architecture, offering substantial efficiency gains, especially for on-device and edge deployments. They excel in tasks like document understanding and visual counting.
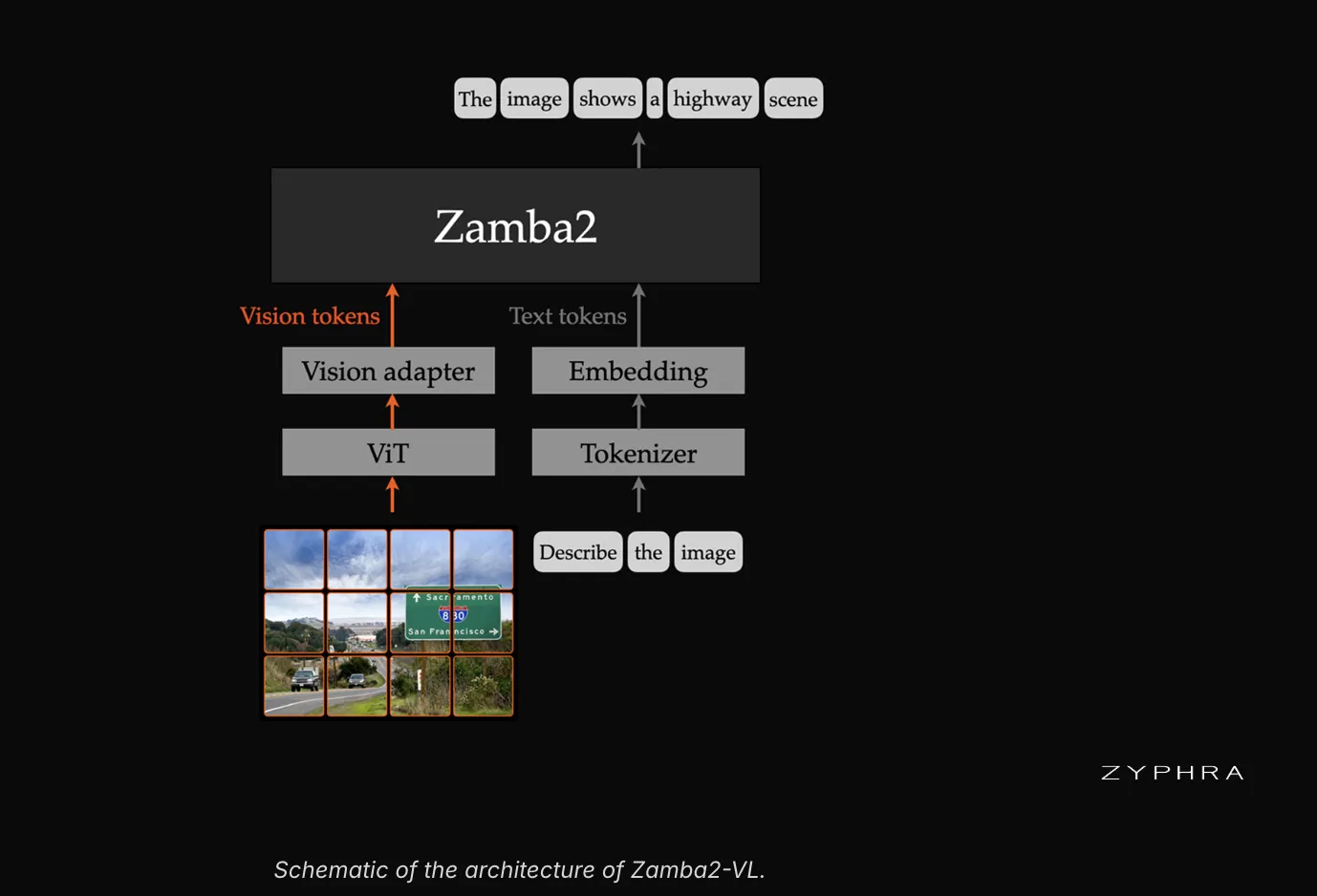
Zyphra has introduced Zamba2-VL, a new series of open vision-language models available in 1.2B, 2.7B, and 7B parameters. These models are built upon the Zamba2 hybrid state-space model (SSM)–Transformer backbone, aiming to provide competitive accuracy with significantly lower latency compared to traditional Transformer-based VLMs.
The core innovation of Zamba2-VL lies in its hybrid architecture, which combines Mamba2 state-space layers with interleaved shared Transformer blocks. This design allows Zamba2-VL to handle the bulk of computation efficiently while retaining the in-context retrieval capabilities often lost in pure SSM models. The Mamba2 layers ensure near-linear time prefill and a fixed-size recurrent state, addressing the quadratic scaling issue of Transformer attention with sequence length.
Zamba2-VL demonstrates strong performance in specific areas despite sometimes lagging larger baselines in knowledge-heavy reasoning tasks. Notably, it excels in visual counting and document understanding, achieving high scores in benchmarks like PixMoCount and DocVQA. This makes it particularly suitable for applications such as invoice parsing, receipt digitization, retail inventory counting, and object grounding.
The primary advantage of Zamba2-VL is its inference efficiency, particularly its reduced time-to-first-token. This efficiency is most pronounced at the 1.2B and 2.7B scales, making these models ideal for on-device and edge deployments like mobile phones and edge boxes. The ability to process long visual inputs, such as multi-page PDFs, also greatly benefits from its linear-time prefill.
For developers, the models are accessible via the Zyphra Zamba2-VL collection on Hugging Face, requiring a specific fork of the Transformers library due to optimized Mamba2 kernels. A CUDA GPU is recommended for optimal latency. The models support both single and multi-image understanding and grounding, offering flexibility for various multimodal applications.
Related articles
The AI world is getting ‘loopy’
AI models are taking a significant leap forward with the adoption of "agentic loops," where AI agents continuously prompt each other to improve code and solve complex problems. This approach, though potentially resource-intensive, promises to unlock new levels of autonomous problem-solving and efficiency in AI applications.
Codex-maxxing for long-running work
Codex is increasingly being used by organizations to support long-running projects that go beyond a single prompt. This whitepaper by Jason Liu offers practical strategies for leveraging Codex as a persistent workspace, managing complex workflows and sustaining progress.
Nobel laureate John Jumper is leaving DeepMind for rival Anthropic
Nobel laureate John Jumper is departing Google DeepMind to join its competitor, Anthropic, after dedicating nearly nine years to DeepMind, where he led the AlphaFold team. Jumper, who shared a Nobel Prize for his work on AlphaFold, expressed gratitude for his time at DeepMind while looking forward to new endeavors.